12. Policies
Policies
Recall from the Reinforcement Learning lesson that a solution to a Markov Decision Process is called a policy, and is denoted with the letter \pi .
Definition
A
policy
is a mapping from states to actions. For every state, a policy will inform the robot of which action it should take.
An
optimal policy
, denoted
\pi^*
, informs the robot of the
best
action to take from any state, to maximize the overall reward. We’ll study optimal policies in more detail below.
If you aren’t comfortable with policies, it is highly recommended that you return to the RL lesson and re-visit the sections that take you through the Gridworld Example, State-Value Functions, and Bellman Equations. These lessons demonstrate what a policy is, how state-value is calculated, and how the Bellman equations can be used to compute the optimal policy. These lessons also step you through a gridworld example that is simpler than the one you will be working with here, so it is wise to get acquainted with the RL example first.
Developing a Policy
The image below displays the set of actions that the robot can take in its environment. Note that there are no arrows leading away from the pond, as the robot is considered DOA (dead on arrival) after entering the pond. As well, no arrows leave the goal as the path planning problem is complete once the robot reaches the goal - after all, this is an episodic task .
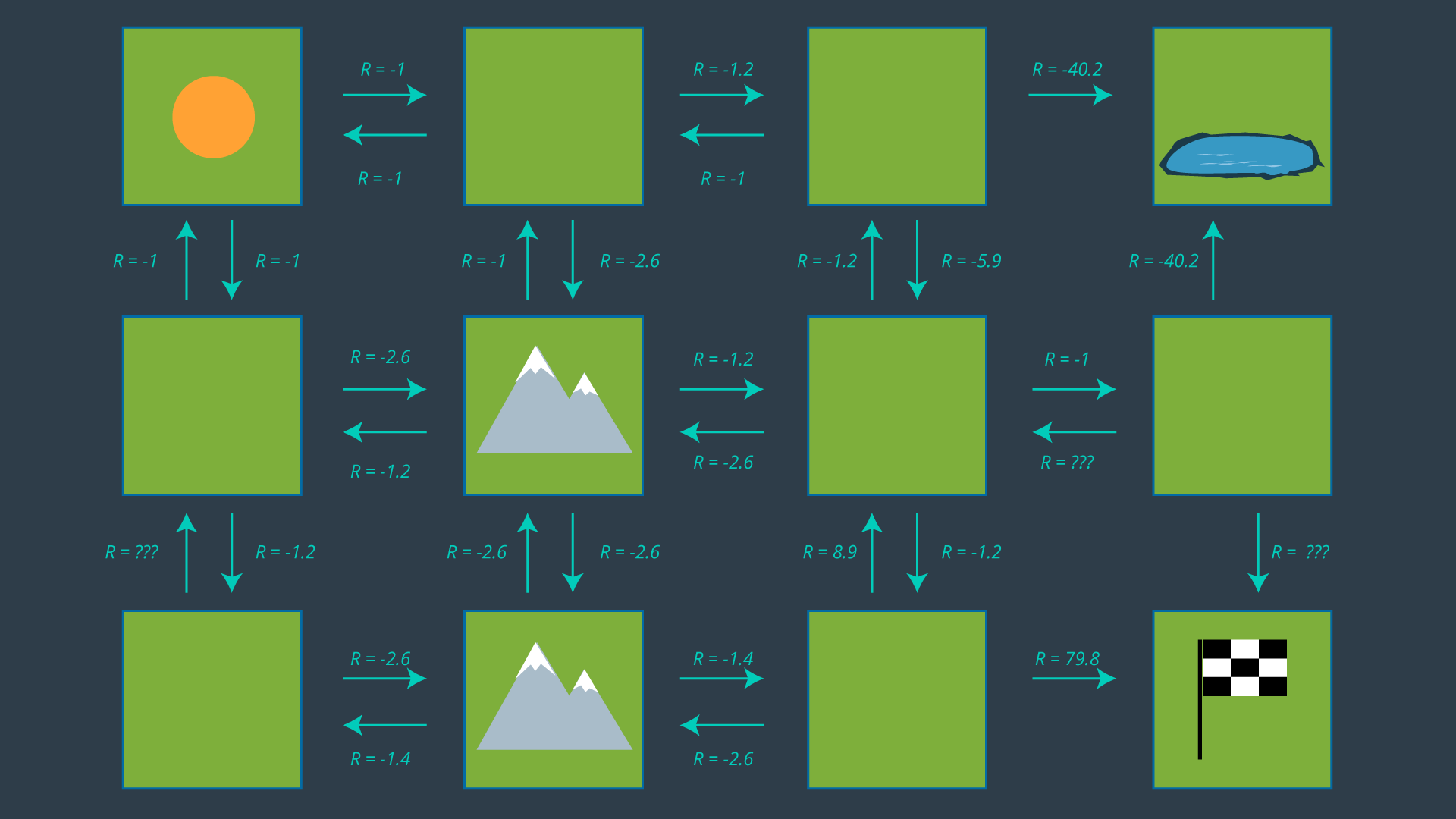
From this set of actions, a policy can be generated by selecting one action per state. Before we revisit the process of selecting the appropriate action for each policy, let’s look at how some of the values above were calculated. After all, -5.9 seems like quite an odd number!
Calculating Expected Rewards
Recall that the reward for entering an empty cell is -1, a mountainous cell -3, the pond -50, and the goal +100. These are the rewards defined according to the environment. However, if our robot wanted to move from one cell to another, it it not guaranteed to succeed. Therefore, we must calculate the expected reward , which takes into account not just the rewards set by the environment, but the robot's transition model too.
Let’s look at the bottom mountain cell first. From here, it is intuitively obvious that moving right is the best action to take, so let’s calculate that one. If the robot’s movements were deterministic, the cost of this movement would be trivial (moving to an open cell has a reward of -1). However, since our movements are non-deterministic, we need to evaluate the expected reward of this movement. The robot has a probability of 0.8 of successfully moving to the open cell, a probability of 0.1 of moving to the cell above, and a probability of 0.1 of bumping into the wall and remaining in its present cell.
All of the expected rewards are calculated in this way, taking into account the transition model for this particular robot.
You may have noticed that a few expected rewards are missing in the image above. Can you calculate their values?
Expected Reward Quiz
QUESTION:
What is the expected reward for moving from the bottom-left cell to the cell above it?
SOLUTION:
NOTE: The solutions are expressed in RegEx pattern. Udacity uses these patterns to check the given answer
QUESTION:
What is the expected reward for moving from the empty cell on the right to the goal,one cell below it?
SOLUTION:
NOTE: The solutions are expressed in RegEx pattern. Udacity uses these patterns to check the given answer
QUESTION:
What is the expected reward for moving from the empty cell on the right to the cell to its left?
SOLUTION:
NOTE: The solutions are expressed in RegEx pattern. Udacity uses these patterns to check the given answer
Hopefully, after completing the quizzes, you are more comfortable with how the expected rewards are calculated. The image below has all of the expected rewards filled in.
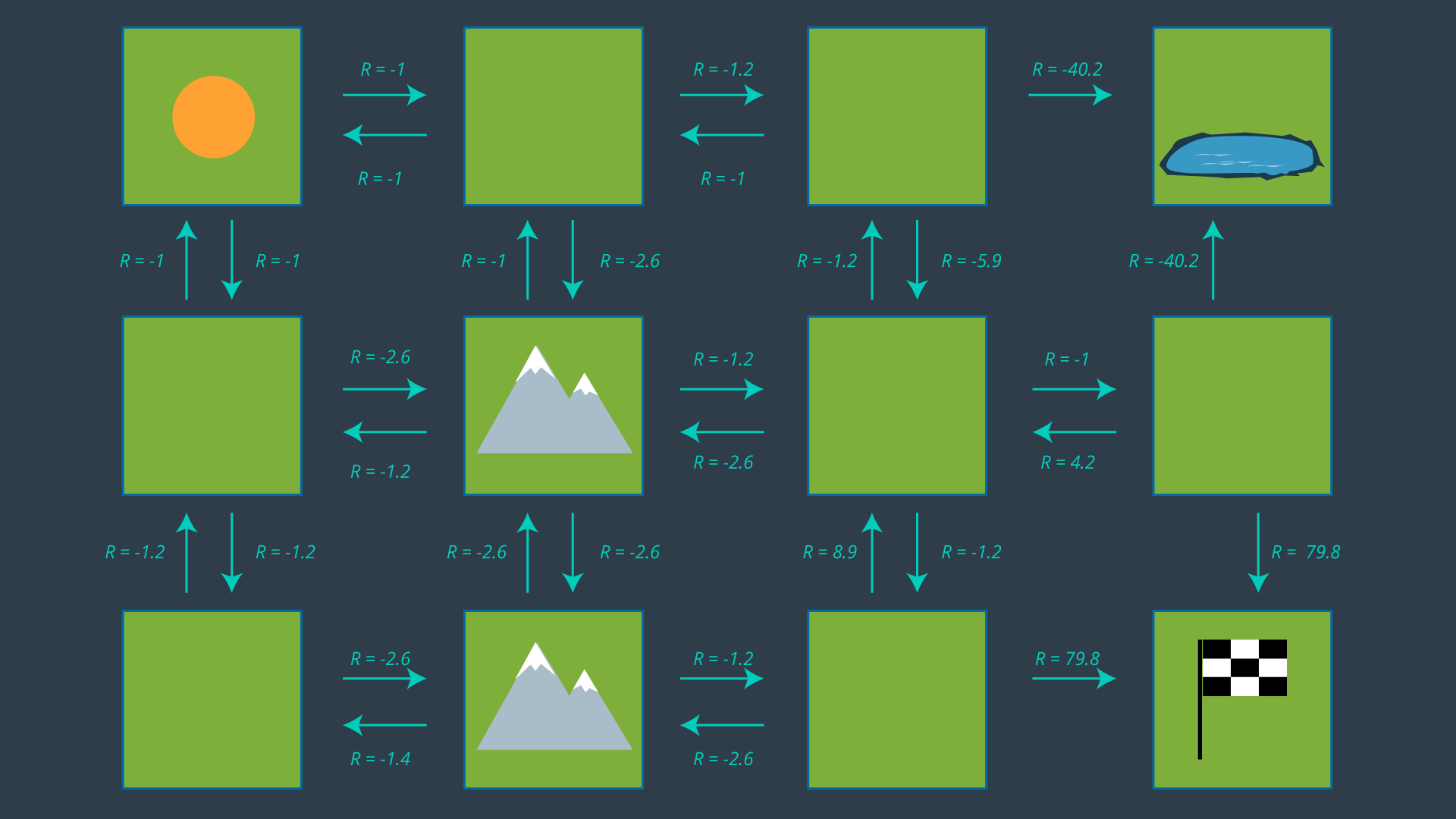
Selecting a Policy
Now that we have an understanding of our expected rewards, we can select a policy and evaluate how efficient it is. Once again, a policy is just a mapping from states to actions. If we review the set of actions depicted in the image above, and select just one action for each state - i.e. exactly one arrow leaving each cell (with the exception of the hazard and goal states) - then we have ourselves a policy.
However, we’re not looking for any policy, we’d like to find the optimal policy. For this reason, we’ll need to study the utility of each state to then determine the best action to take from each state. That’s what the next concept is all about!